
Have you wondered whether there could be an ultimate solution to speed up algorithms through parallelizing computing, Pandas, and NumPy? Can you boost the speed by integrating all of these data frames with libraries like XGBoost or Sklearn? Well, then it will be possible in real-time with the help of Dask.
There are various solutions available in the market which are parallelizable and yet not clearly transforming into a significant data frame computation. In current times, the enterprises are willing to solve their problems by writing custom code with the help of low-level systems like MPI, heavy lifting and queuing complex systems using MapReduce or Spark.
What is a Dask and how is it utilised?

The Dask data frame allows their users to work as substitute of clusters with a single-machine scheduler as it does not require any prior setups. Henceforth, these schedulers run entirely within the same process as the user’s session.
These data frames are useful in data science as they coordinate with other Panda series that are arranged with the index. A Dask is mainly partitioned row-wise and the rows are grouped by index value for better efficiency.
Dask is simply a revolutionary tool, and if you have been loving Pandas and Numpy and hate struggling with the data that does not fit into RAM, it is the perfect solution. Developers only want to write the code once and deploy it on a multi-node cluster by making use of standard Pythonic syntax. The magical feature is that it allows minimal code changes and also you can run the code in parallel taking advantage of the processing power.
In this article, we will be looking at how easily the dask data frames fit into the data science workflow.
Let us have a brief idea to give an indication of a completely natural and unobtrusive syntax to start with the Dask. The main task is to use the knowledge which you possess without learning a new big data tool like Hadoop or Spark.
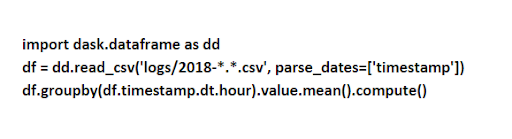
Dask introduces three parallel collections which are capable enough to store data, which is more significant than RAM called Arrays, Bags, and Dataframes. Each collection possesses unique types that are used to partition the data between RAM and a hard disk across multiple nodes in a cluster. The data frames comprise of small and split up Pandas data frames which allow forming a subset of Pandas query syntax. We can see an example code that is used to load all CSV files and also parses the timestamp field by running a Pandas query.
Dask Arrays support Numpy like slicing as mentioned in the code example where an HDF5 dataset is chunked into dimension blocks of (5000,5000):

The Dask data frame also faces some limitations as it can cost you more bucks to set up a new index from an unsorted column. As the Pandas API is vast, the Dask DataFrame make no attempt to implement multiple Pandas features, and where Pandas lacked speed, that can be carried on to Dask DataFrame as well.
Why event stream processing is leading the new ‘big data’ era
What is Dask for machine learning?
Any machine learning project is likely going to suffer from factors — long training times and large datasets. Dask can handle both these problems as it is easy to use Dask workflows for preparing and setting up data to deploy XGBoost or Tensorflow and hand over the data. Numpy arrays are replaced with Dask arrays, which helps to scale your algorithms much easier.
For most of the cases, Dask for machine learning offers a single unified interface around the similar Pandas, Scikit-Learn and NumPy APIs. If you are familiar with the Scikit-Learn then it feels home working with Dask-ML. Also, it possess different methods from scikit-learn for searching hyperparameter such as RandomizedSearchCV and GridSearchCV to much more.

AI, machine learning and Python: Let’s see how far they can go
Summing up!
Even after discovering exciting features about the Dask, Pandas still unless it fits into the user’s RAM. There are few functions which do not work with the Dask data frame; to resolve this, dask.delayed provides many flexible solutions by letting the user know how to use the disk in a selective way. This helps to perform computations in the data frame by chunking all of the data from disk and moving forward with important process by shedding off the middle values.
The active participation of the Dask community level has contributed a lot more to because of the way it has evolved within its own ecosystem. Such a unique feature allows the whole ecosystem to gain benefits from parallel and distributed computing with minimal coordination. As an end result, the developer community is pushing forward the Dask development to make sure the Python environment evolves with a steady consistency. Keep Learning!
Author Bio
Stephanie Donahole is working as a Business Analyst at Tatvasoft.com.au, a web development company in Melbourne, Australia. She loves to write about technology innovation and emergence. Follow Her on Twitter at @SDonahole.







