
Here’s an example of a workplace situation that arises because of a lack of file locking.
At 4:14 p.m. in Tokyo, Aiko stared at her screen, zooming in on the north wing of Quanta Structures’ latest skyscraper. She tweaked a structural column to reinforce the cantilevered floors above, using the latest seismic model. A simple change, but vital. She saved her update and moved on.
Six time zones away, in a quiet office in London, Marcus was making his own edits. He didn’t see Aiko’s update; he couldn’t have as his file copy was from an hour earlier. He adjusted the panel spacing, tweaked the glass spec, and hit save.
Just like that, Aiko’s reinforcement was gone. With no alert or warning, the file synced. On the surface, the design still looked fine, but it wasn’t.
Welcome to the high-stakes world of distributed systems, where you can’t have everything that you want. Enter the CAP theorem, a reality check that forces tough choices on anyone building systems that span the globe.
The CAP theorem: the triangle of trade-offs
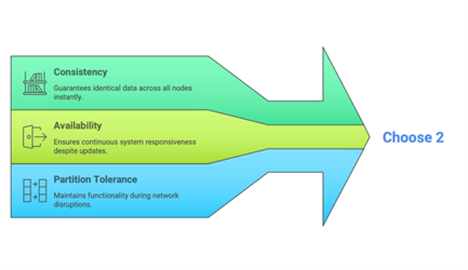
The CAP theorem, Eric Brewer’s big idea from 2000, proven soon after by Seth Gilbert and Nancy Lynch, states that a distributed system can only guarantee two of three things: Consistency, Availability, and Partition Tolerance. Let’s break it down.
Picture a distributed system as a chain of libraries around the world, all tasked with maintaining the same book catalogue. Here’s what each piece of the triangle represents:
- C – Consistency: Every library displays the exact same catalogue, updated instantly. No discrepancies, no errors. Tokyo’s list matches New York’s.
- A – Availability: Every library is accessible every time you visit, even if the information is slightly outdated. The doors are always open.
- P – Partition Tolerance: The libraries continue operating even if the internet connections between them go down. Maybe New York can’t reach London, but both remain functional, even if their catalogues temporarily diverge.
Network partitions, such as outages, broken lines, and single site failures, aren’t uncommon. They’re a fact of life. Since they can’t be ignored, the ‘P’ partition tolerance isn’t truly optional. That means you have to choose between consistency and availability. Do you keep the doors open at the risk of potentially delivering stale data? Or do you lock them until you’re certain everyone’s on the same page?
Let’s see how this plays out with something as simple, but as fraught, as file locking.
File locking: the digital referee
File locking prevents teams from accidentally overwriting each other’s changes to shared files. In a single office, it’s simple. Open a file, and the system puts a ‘do not disturb’ sign on it. If your coworker tries to edit, they get an error: ‘File in use’. This is effective, and everyone’s safe.
But distributed systems don’t work that neatly. Quanta Structures has files on servers worldwide, with teams in different time zones. What happens if the network between those servers cuts out? Do you let people keep working, risking conflicts, or do you block edits and potentially halt work? This is the CAP theorem in action, shaping every file lock.
Strict locking
Strict locking prioritises consistency, even if it means reduced availability. Only one person can edit at a time, and every server must agree before changes go through. Imagine a bank vault: only one person is allowed in at a time while everyone else waits. For critical files, like Aiko’s blueprint, this is non-negotiable.
But there’s another cost to strict global locking that’s easy to overlook, and that’s latency.
Even when the network is working, coordinating a global lock isn’t instant. It’s limited by the speed of light and the physical distance between locations. And physics doesn’t negotiate.
Let’s break that down. The speed of light through fibre is very fast, about 200,000 kilometres per second. Tokyo to London is roughly 9,600 kilometres one way. This means that, best case, there will be a 48-millisecond one-way latency. That’s 96 milliseconds round trip, before factoring in real-world overhead like routing, switching, and protocol handshakes. In practice, you’re looking at 200 to 250 milliseconds, easily.
Now consider what that means for file locking. A naïvely designed, single-threaded application that isn’t built to tolerate latency can’t take or release more than four or five locks per second at best. And that’s under ideal conditions. For large files, where meaningful changes need to be synced, the throughput drops even further.
Now imagine every time someone in Tokyo wants to save a file. That request needs to make a round trip to and from London, or worse, coordinate with multiple global sites. This might not sound like much, but due to the way many traditional file-based apps are designed, that delay adds up fast. Click, wait. Click again, wait more. What feels fine in a web browser can feel broken in a desktop app expecting local speeds. Suddenly, your sleek engineering workstation starts acting like it’s stuck in 1998.
Why? Because most of these apps assume the file server is in the same room, or at least on the same local network. They’re built for sub-millisecond latency. Introduce global round trips into that equation, and the experience breaks down.
That’s the often-hidden tax of strict global locking. Every change, every save, every lock, coordinated, confirmed, delayed.
Smarter strict locking: opportunistic locks (oplocks)
To make global locking a little more usable, some systems use smarter strategies like opportunistic locking, or oplocks.
Oplocks are a kind of optimistic agreement. The server lets the client act as if he or she has exclusive access to the file, as if they ‘own’ it temporarily. This allows the client to cache changes locally and work at full speed, without needing permission for every little operation. As long as no one else tries to open the file, things stay fast and quiet. If another user does need access, the server signals: “You’re not alone anymore.” The client syncs, hands back control, and coordination resumes.
The beauty of oplocks is that they avoid unnecessary round trips when there’s no contention for a file. In most cases, where a file is being edited by just one person or team, there’s no noticeable delay. The system only pays the latency cost when it really matters: during a conflict.
But an oplock is still a lock. If the client holding it goes offline, crashes, or loses connectivity, the server can’t easily revoke that lock without risking loss of consistency. Other users won’t be able to edit the file until the oplock is released and the modified data synced. So, while oplocks hide latency under ‘single editor’ conditions, they don’t eliminate the challenges of distributed coordination, they just defer them.
It’s a clever compromise that improves performance most of the time, but it still lives within the same constraints imposed by the CAP theorem. You can delay the pain, but you can’t always avoid it.
Eventual consistency: the collaborative canvas
On the other end of the spectrum is eventual consistency, which prioritises availability and partition tolerance. Think of a shared online document, like a team brainstorming session captured in a cloud-based note-taking app. Multiple users can edit simultaneously, with conflicts detected, and the system resolves them later, either automatically or through manual intervention. This approach keeps workflow continuity, even during network partitions, because each server operates independently, syncing changes when connectivity returns.
Eventual consistency is the backbone of tools like shared document platforms like Google Docs or Dropbox, where speed, productivity and continuous access trump perfect real-time synchronisation. But it’s not without risks. What if two designers tweak the same section of a presentation, and their changes clash? The system might create conflicting versions, requiring a time-consuming resolution and human intervention. For non-critical files, like meeting notes or draft proposals, this is manageable. But merging two conflicting changes to a complex engineering model can feel like trying to stitch together two different paintings of the same landscape: messy and error-prone.
What happens when the network fails?
Let’s say Quanta Structures has offices in New York, London, Tokyo, and Sydney, each with its own file server. Most shared files are edited locally; London staff use the London server, and so on. If someone tries to open a file that’s already in use, Windows SMB (our example protocol, since it’s most common) ensures they see a clear ‘file in use’ message.
But what if the wide-area network goes down? Tokyo can’t see the other offices, but their local server is still running. Should Tokyo’s team keep working? If they do, their changes might collide with edits made in New York or London once connectivity is restored. If you block edits, productivity tanks, even though the server is right there.
This is the CAP theorem again. You either prioritise consistency and risk a work stoppage, or prioritise availability and risk conflicts. Neither answer is perfect.
A granular approach: precision in a complex world
In an ideal world, I’d prefer automatic solutions: ones that adapt on their own, minimise administrator involvement, and simply work. But the CAP theorem stands in the way. When consistency, availability, and partition tolerance are at odds, there’s no universal setting to handle every scenario. Trade-offs are necessary, and someone must decide where to draw the line.
The answer lies in granularity, tailoring file locking to the specific needs of each file or folder. Not all files are created equal. A financial report edited across regions requires strict consistency to avoid costly errors. On the other hand, a team’s shared brainstorm document can tolerate temporary inconsistencies; conflicts can be resolved later. A one-size-fits-all approach, whether it’s strict locking or eventual consistency, just doesn’t cut it.
A granular locking strategy enables administrators to apply strict locking where it truly matters, e.g., engineering blueprints, legal contracts, critical financial models that are co-edited by global teams. For these, we choose consistency, even at the expense of availability. In most other cases, eventual consistency keeps collaboration smooth, even during network disruptions. Within a single office, where latency and partitions aren’t significant issues, strict locking can be enforced with minimal downside. But across global sites, the mix has to be more deliberate. Yes, it takes planning, but we’re up against the laws of physics. There’s no checkbox for that.
Embracing the art of compromise
The CAP theorem feels somewhat unfair in our global world, where it seems like anything should be possible. But, between us, wouldn’t it be nice if other business areas had mathematical theorems that clearly told us what is and isn’t possible?
In distributed systems, the reality is you can’t have it all. Consistency, availability, and partition tolerance form a triangle of trade-offs, and file locking is where those choices become real.
Strict locking offers the security of a bank vault, but it can block teams from accessing their work. Eventual consistency keeps the collaborative space open, but it risks messy conflicts. A granular approach bridges those extremes, providing the precision and flexibility necessary to support the way people actually work.
So, the next time you’re editing a shared file across continents, ask yourself: is this a structural blueprint that demands perfection, or a document that can tolerate the occasional conflict? The answer will shape your locking strategy.
Aron Brand is CTO of Ctera.
Read more
Combining block, file and object storage in one cluster technology – Software-defined data storage from start-up Simplyblock brings together three main storage types in one platform, saving time for businesses



